1. I think 4 rows should be fine given that you have 24 different versions of the survey, therefore your total design consists of 4*24 different choice tasks. Of course the efficiency is lower when using 4 rows because you get half the amount of information
2. That would be possible. Given that you will have 48 different blocks, it is to be expected that some blocks may have very few respondents (perhaps even none), and that is fine, there is enough information in your data to not having to worry about missing blocks.
3. Yes attribute level balance is not really important, it is a nice to have feature but has little to no influence on your model, so if you prefer to have 5 choice tasks over 4 then please do so. If you are using the mfederov algorithm, then you can use something like bprice * price[1,2,3,4](1-2,1-2,1-2,1-2) to indicate that you would like to have each level appearing 1 or 2 times. If you use the default swapping algorithm, then you need to be aware of the fact that it will use levels 1,2,3,4,1 (it cycles through levels) looking at the order in which the levels appeared, so it will always have the first level twice. In that case, you may want to vary the order in which attribute levels appear in the syntax, e.g. bprice * price[2,4,1,3]. You could overcome these issues by simply creating 5 price levels.
I would prefer option 2 or 3. Option 2 is likely the hardest one to implement, having 48 different versions. Option 3 would also be fine if you think that having 5 choice tasks per respondent is doable as it will provide more information in your data.
Michiel
Pivot design on the fly (heterogeneous) and effects coding
Moderators: Andrew Collins, Michiel Bliemer, johnr
14 posts
• Page 2 of 2 • 1, 2
Re: Pivot design on the fly (heterogeneous) and effects codi
![]() by Michiel Bliemer » Wed May 27, 2020 1:08 pm
by Michiel Bliemer » Wed May 27, 2020 1:08 pm
- Michiel Bliemer
- Posts: 1885
- Joined: Tue Mar 31, 2009 4:13 pm
Re: Pivot design on the fly (heterogeneous) and effects codi
![]() by xdupom » Wed May 27, 2020 8:09 pm
by xdupom » Wed May 27, 2020 8:09 pm
Many thanks for your quick answer! Very helpful!
Using blocks (option 2) does increase efficiency compared to option 3 where I only have 5 rows. So I might go for option 2 even though it is harder. It would not be that hard if I could trick Ngene to generate the choice sets of block 1 first (i.e. scenarios 1 to 4) followed by the choice sets of block 2 (i.e. scenarios 5 to 8). Can I control that in Ngene?
More concretely if I was not clear enough: when I generate my design with 8 rows, 2 blocks, Ngene gives me a table with disordered scenarios in terms of blocks (see last column of first table below) whereas, to make it easier, I would rather have ordered scenarios where the 4 first presented scenarios are for block 1 and the 4 last scenarios for block 2 (like in the second table below, last column). Please click on the picture below to see the entire table (and therefore the last column).
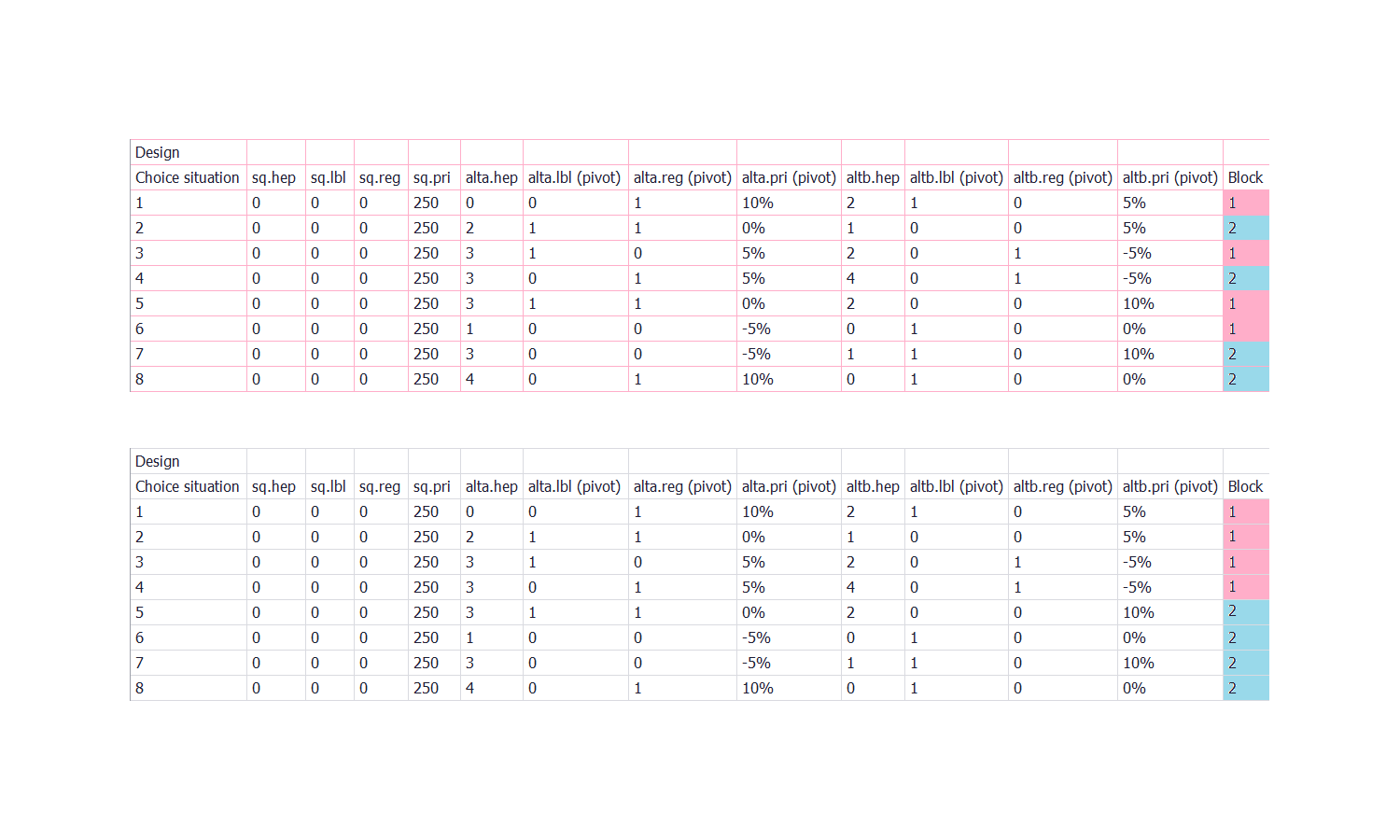
Is it feasible to ask Ngene to order scenarios into blocks?
My code below if ever it helps (I use the mfederov algorithm).
Many thanks again.
Best,
Marion
Using blocks (option 2) does increase efficiency compared to option 3 where I only have 5 rows. So I might go for option 2 even though it is harder. It would not be that hard if I could trick Ngene to generate the choice sets of block 1 first (i.e. scenarios 1 to 4) followed by the choice sets of block 2 (i.e. scenarios 5 to 8). Can I control that in Ngene?
More concretely if I was not clear enough: when I generate my design with 8 rows, 2 blocks, Ngene gives me a table with disordered scenarios in terms of blocks (see last column of first table below) whereas, to make it easier, I would rather have ordered scenarios where the 4 first presented scenarios are for block 1 and the 4 last scenarios for block 2 (like in the second table below, last column). Please click on the picture below to see the entire table (and therefore the last column).
Is it feasible to ask Ngene to order scenarios into blocks?
My code below if ever it helps (I use the mfederov algorithm).
- Code: Select all
Design
;alts = altA*, altB*, SQ*
;rows = 8
;block = 2
;eff = (mnl,d)
;alg = mfederov
;reject:
altA.Hep = 4 and altA.Lbl<> 0,
altA.Reg = 0 and altA.Hep = 4,
altA.Reg = 1 and altA.Hep = 1,
altB.Hep = 4 and altB.Lbl<> 0,
altB.Reg = 0 and altB.Hep = 4,
altB.Reg = 1 and altB.Hep = 1
;require:
SQ.Hep = 0
;model:
U(SQ) = b0
+ b1.effects[0|0|0|0] * Hep[0,1,2,3,4]
+ b2 * Lbl.ref[0]
+ b3 * Reg.ref[0]
+ b4 * Pri.ref[250]
/
U(altA) = b1 * Hep
+ b2 * Lbl.piv[0,1]
+ b3 * Reg.piv[0,1]
+ b4 * Pri.piv[-5%,0%,5%,10%](2,2,2,2)
/
U(altB) = b1 * Hep
+ b2 * Lbl.piv[0,1]
+ b3 * Reg.piv[0,1]
+ b4 * Pri.piv[-5%,0%,5%,10%](2,2,2,2)
$
Many thanks again.
Best,
Marion
- xdupom
- Posts: 8
- Joined: Thu Apr 23, 2020 4:21 am
Re: Pivot design on the fly (heterogeneous) and effects codi
![]() by Michiel Bliemer » Thu May 28, 2020 1:19 pm
by Michiel Bliemer » Thu May 28, 2020 1:19 pm
Note that an 8-row design is only more efficient because it has more rows than a 5-row design, but PER RESPONDENT the 5-row design is more efficient, the efficiency of the 8-row design needs to be shared across 2 respondents.
It is not possible to let Ngene sort by block, but it is a good comment and I suggest that we implement that in a future version. For the moment, you simply copy the design to Excel and you sort the design in Excel, that should be easy.
Michiel
It is not possible to let Ngene sort by block, but it is a good comment and I suggest that we implement that in a future version. For the moment, you simply copy the design to Excel and you sort the design in Excel, that should be easy.
Michiel
- Michiel Bliemer
- Posts: 1885
- Joined: Tue Mar 31, 2009 4:13 pm
Re: Pivot design on the fly (heterogeneous) and effects codi
![]() by xdupom » Thu May 28, 2020 4:32 pm
by xdupom » Thu May 28, 2020 4:32 pm
Indeed, thanks! Alright I might go the 5 row design then, which is more simple. Again, thank you for your very very valuable help, this is always reassuring. 
Best,
Marion
Best,
Marion
- xdupom
- Posts: 8
- Joined: Thu Apr 23, 2020 4:21 am
14 posts
• Page 2 of 2 • 1, 2
Return to Choice experiments - Ngene
Who is online
Users browsing this forum: No registered users and 48 guests